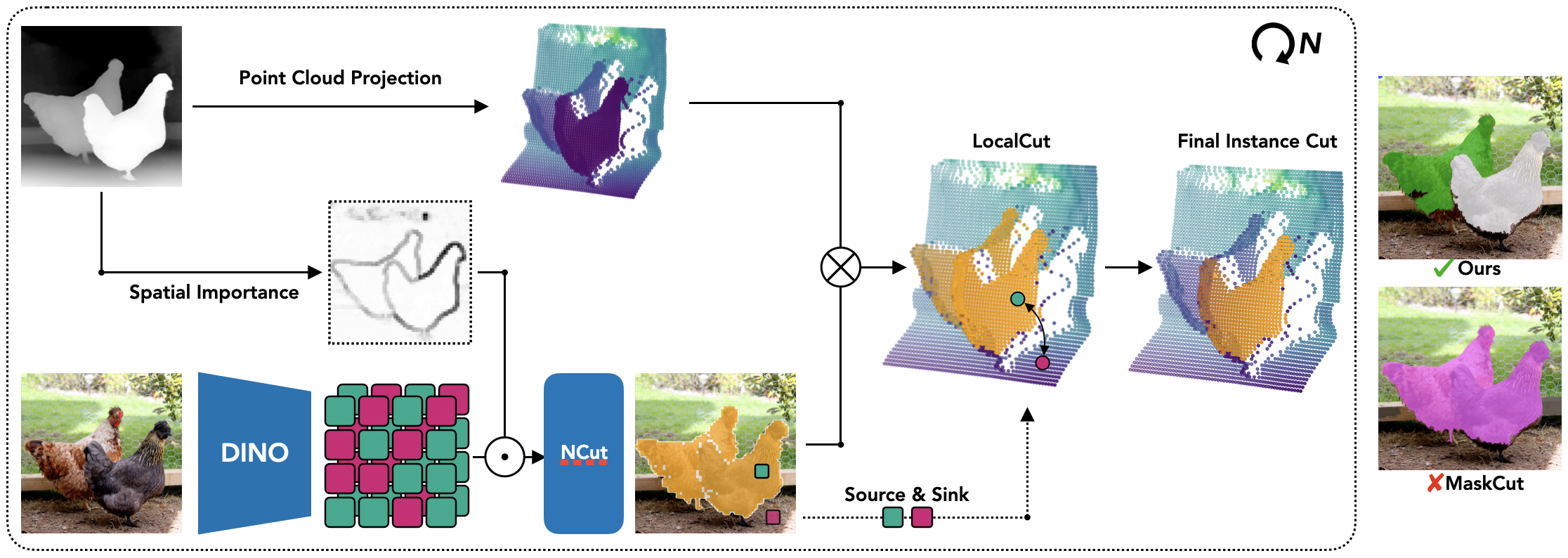
Our method improves instance segmentation by combining semantic and 3D spatial information. While existing methods often fail to separate connected, semantically similar instances in 2D, we address this by leveraging a point cloud representation derived from monocular depth estimation. We use NCut to define an initial semantic partition. Further, we project the depth map into a 3D point cloud and construct a nearest-neighbor graph to capture local geometric properties. Instance boundaries are identified using MinCut, which partitions the graph by minimizing edge weights, with foreground and background points defined based on NCut's semantic analysis: The source and sink points are set to the semantically most forward and backward points, respectively.
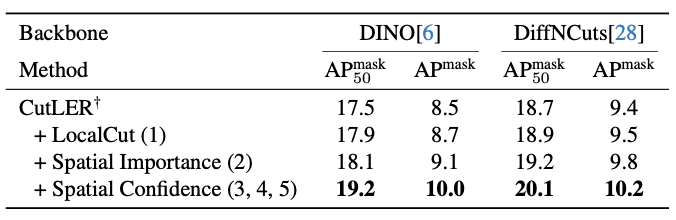
We compute a Spatial Importance map based on depth data, assigning higher importance to regions with rapid depth changes, which likely indicate object boundaries. Inspired by unsharp masking techniques, we apply Gaussian blurring to the depth map and subtract it from the original, revealing high-frequency depth components. These values are normalized and used to sharpen the semantic similarities in the affinity matrix, emphasizing boundaries critical for segmentation. This improved semantic mask ensures LocalCut effectively identifies precise 3D instance boundaries.
Our method refines pseudo-masks used for CAD training by leveraging 3D information to assess their quality through Spatial Confidence maps, which capture certainty for individual patches along 3D boundaries. This process builds on LocalCut, where segmentation sensitivity to thresholds indicates boundary quality. By sampling variations of the threshold, we compute confidence scores that guide mask refinement during training.
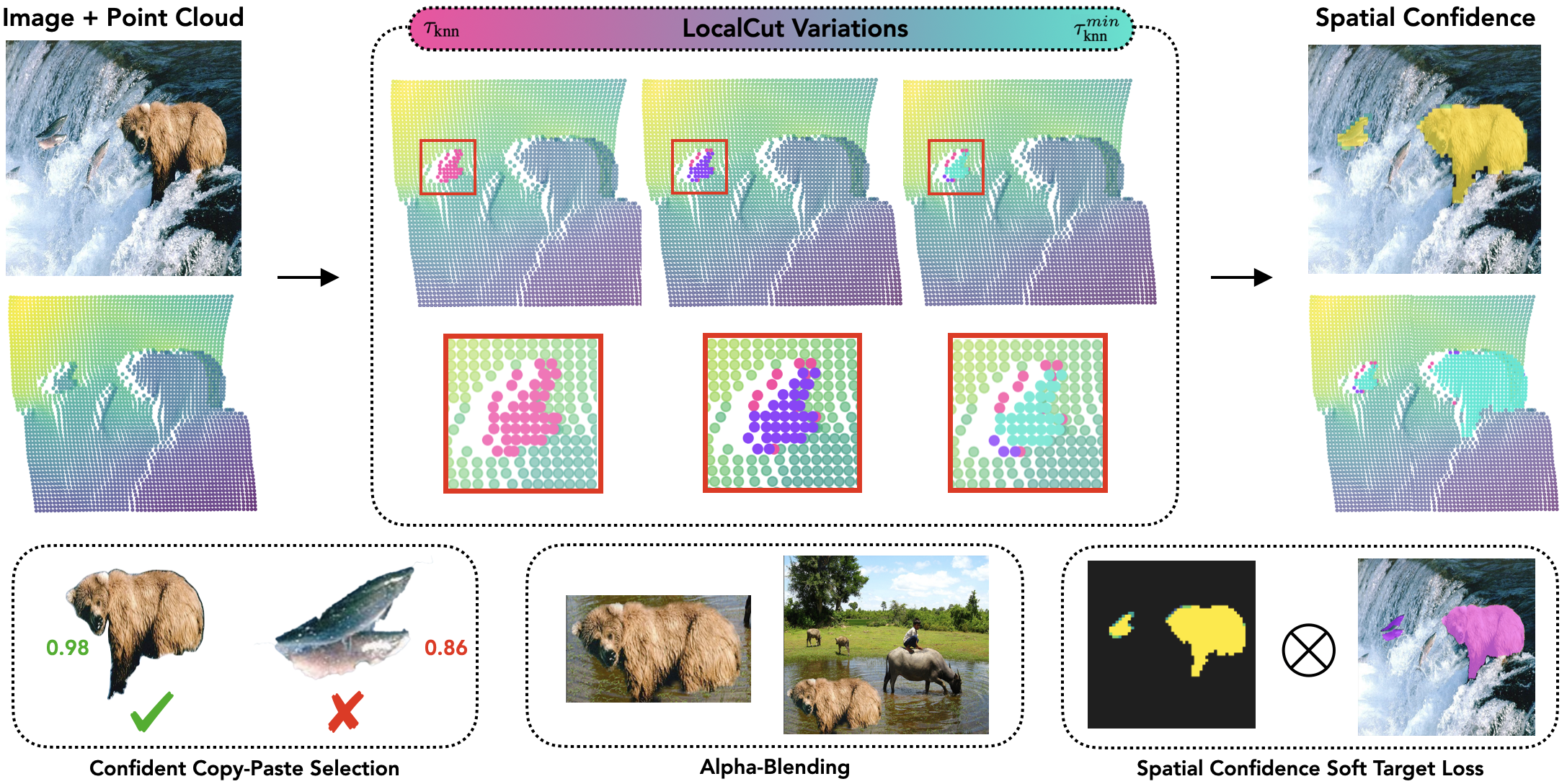
Confident Copy-Paste Selection: We enhance copy-paste augmentation by selecting only the highest-quality masks based on their Spatial Confidence scores. This reduces ambiguity, ensuring only reliable masks are used, resulting in improved CAD performance.
Confidence Alpha-Blending: Instead of binary copy-paste augmentation, we use Spatial Confidence to alpha-blend uncertain regions into the target image. Pixels with high confidence are fully pasted, while lower-confidence areas are partially blended, creating more natural augmentations and further improving model training.
Spatial Confidence Soft Target Loss: We modify the CAD loss function to incorporate patch-level confidence from the Spatial Confidence maps. Each mask region’s loss is weighted by its confidence, providing a more precise learning signal. This re-weighting ensures the model better reflects the reliability of the pseudo-mask regions, leading to more accurate instance segmentation.
By integrating Spatial Confidence maps into these strategies, we significantly enhance the training process, yielding cleaner masks and better segmentation performance.
We train a Cascade Mask R-CNN using our generated IN1K pseudo-masks together with Spatial Confidence and further refine the model with 1 round of self-training.
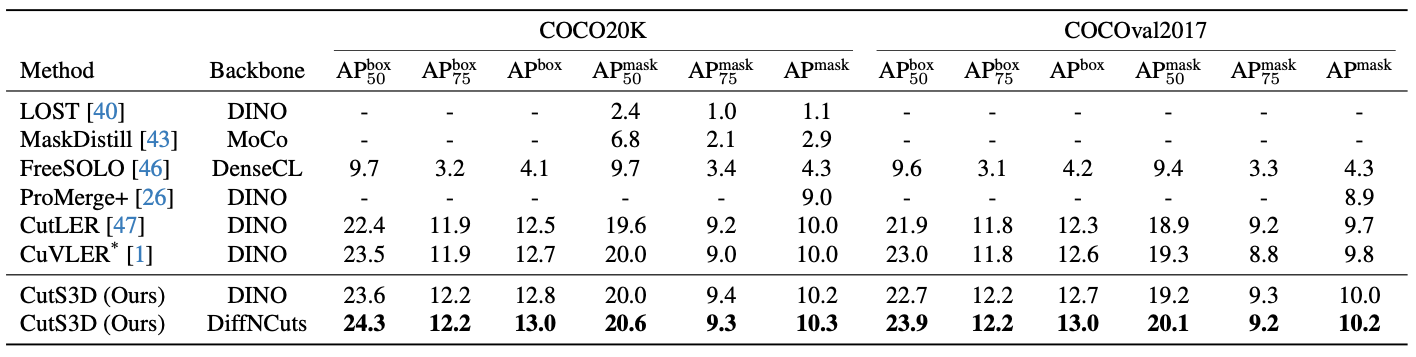
For unsupervised instance segmentation, we outperform the state-of-the-art on the COCO val2017 and COCO20K datasets across a wide range of metrics.
We evaluate our method on different object detection datasets and find that we outperform our baseline, CutLER, on all benchmarks, as well as CuVLER on the most evaluations.
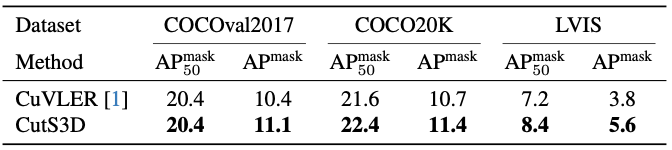
We further self-train our model on the COCO target domain and find that we outperform the state-of-the-art on the COCO val2017, COCO20K and LVIS datasets across a wide range of metrics.