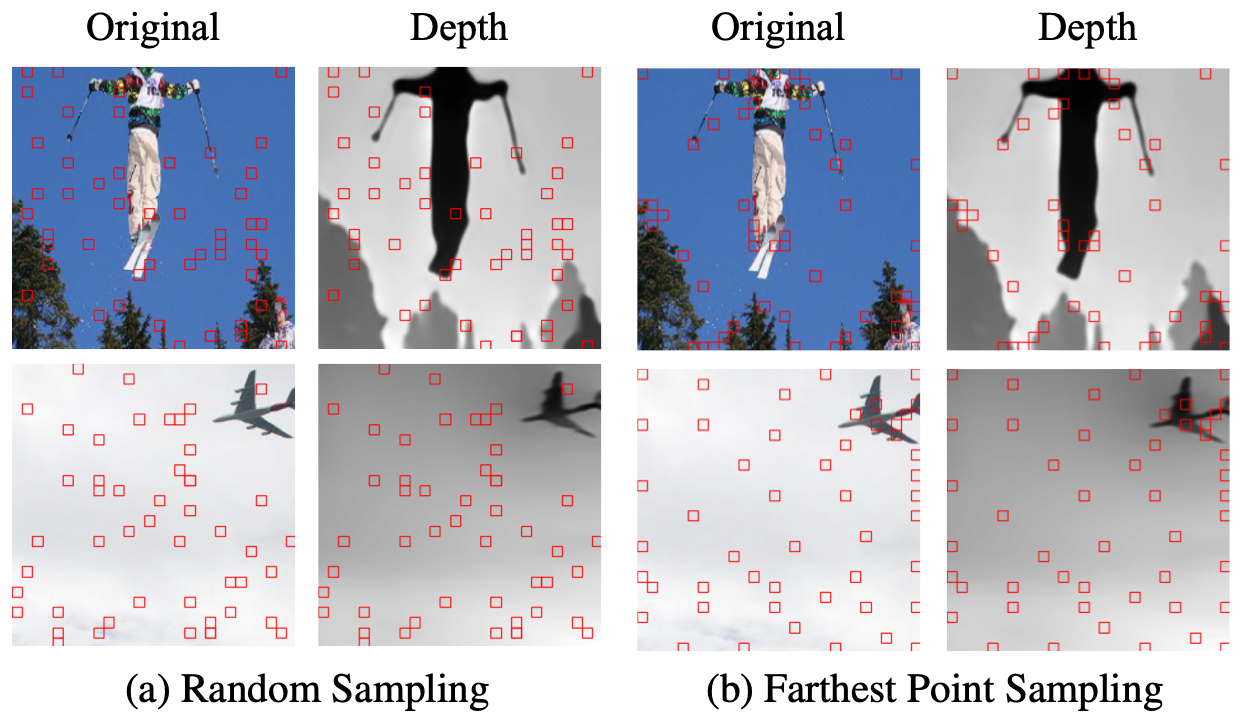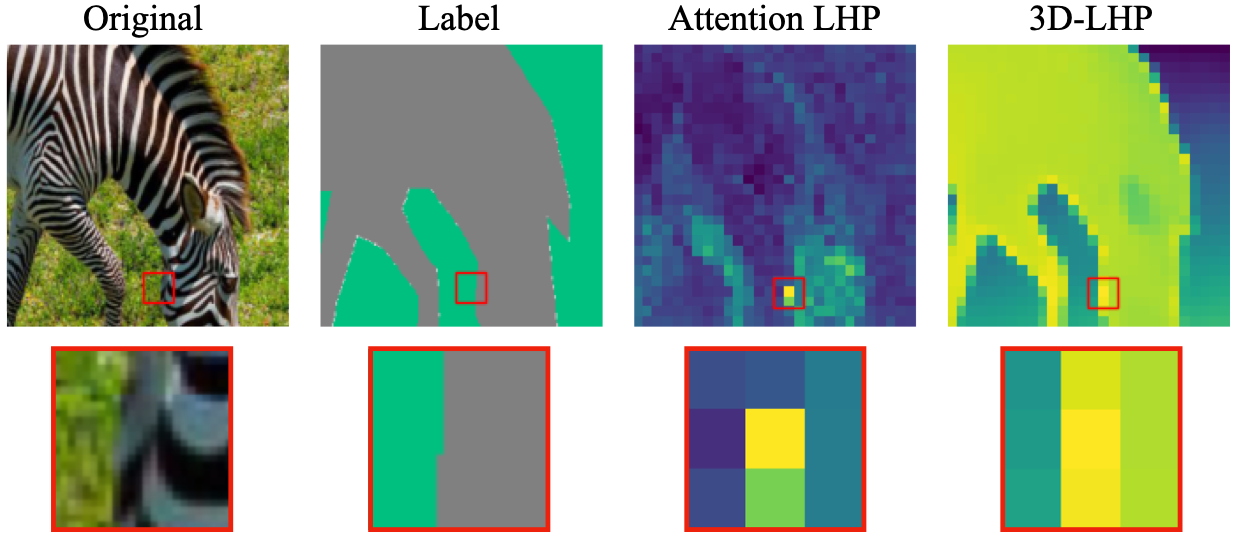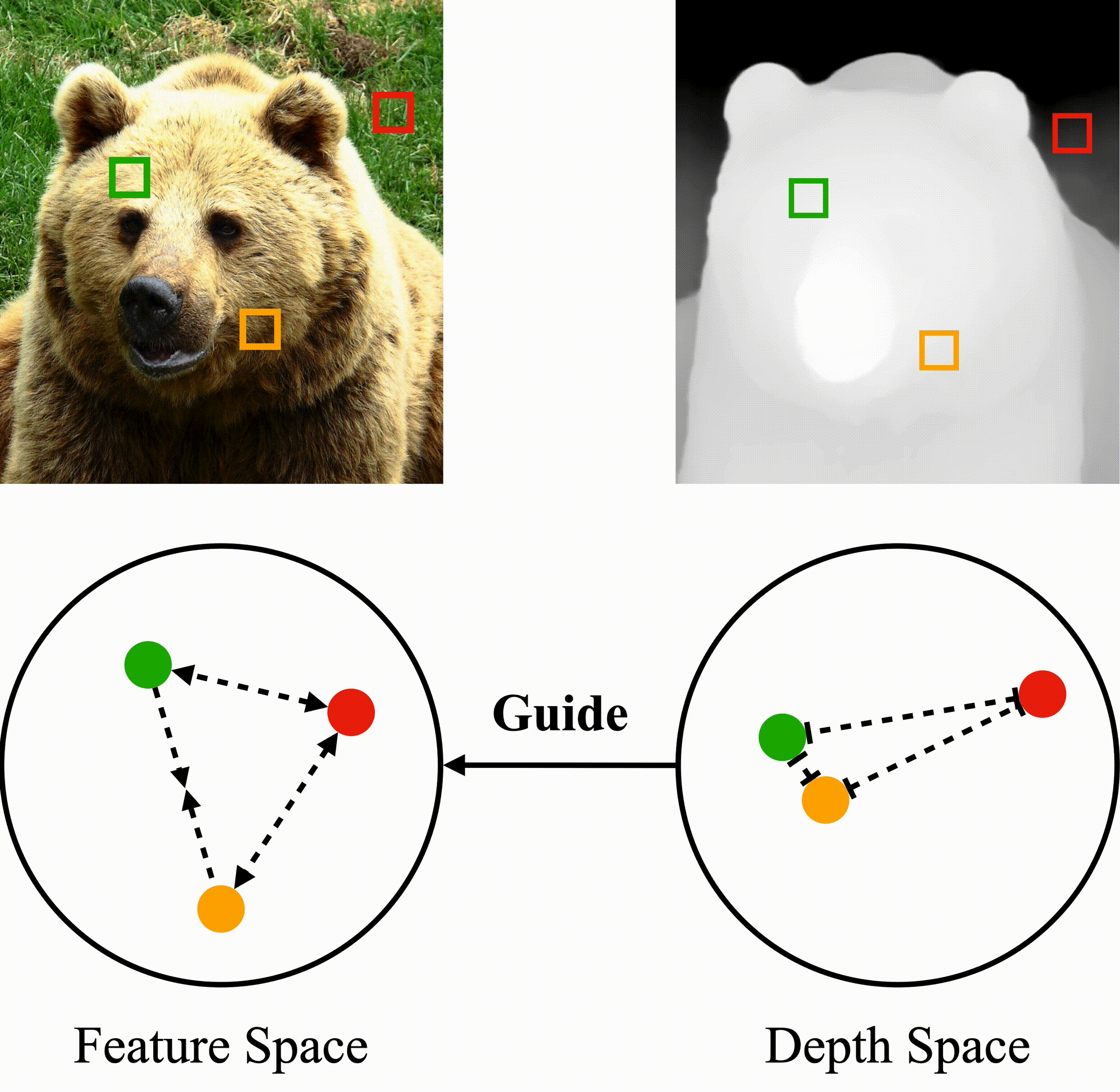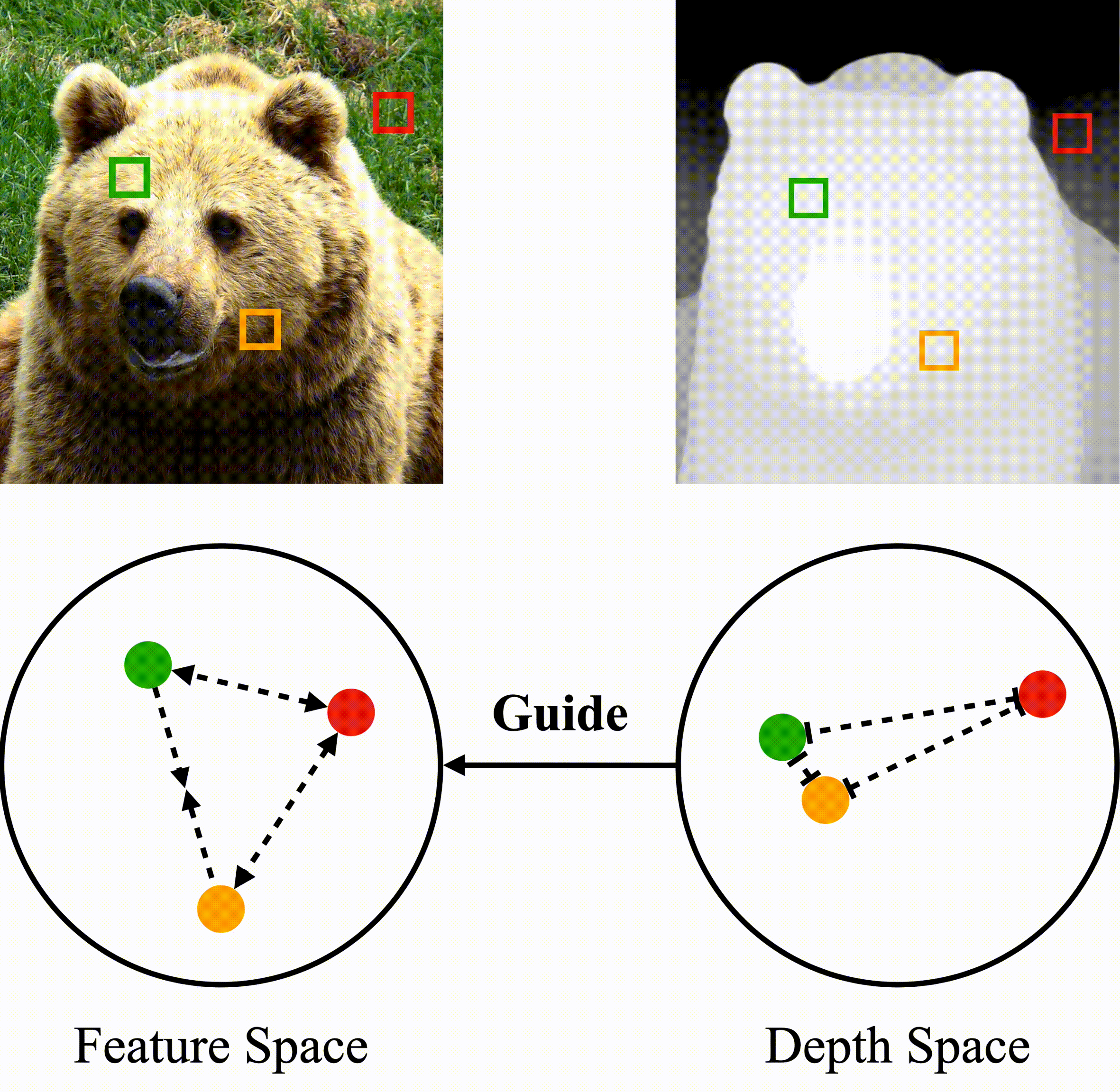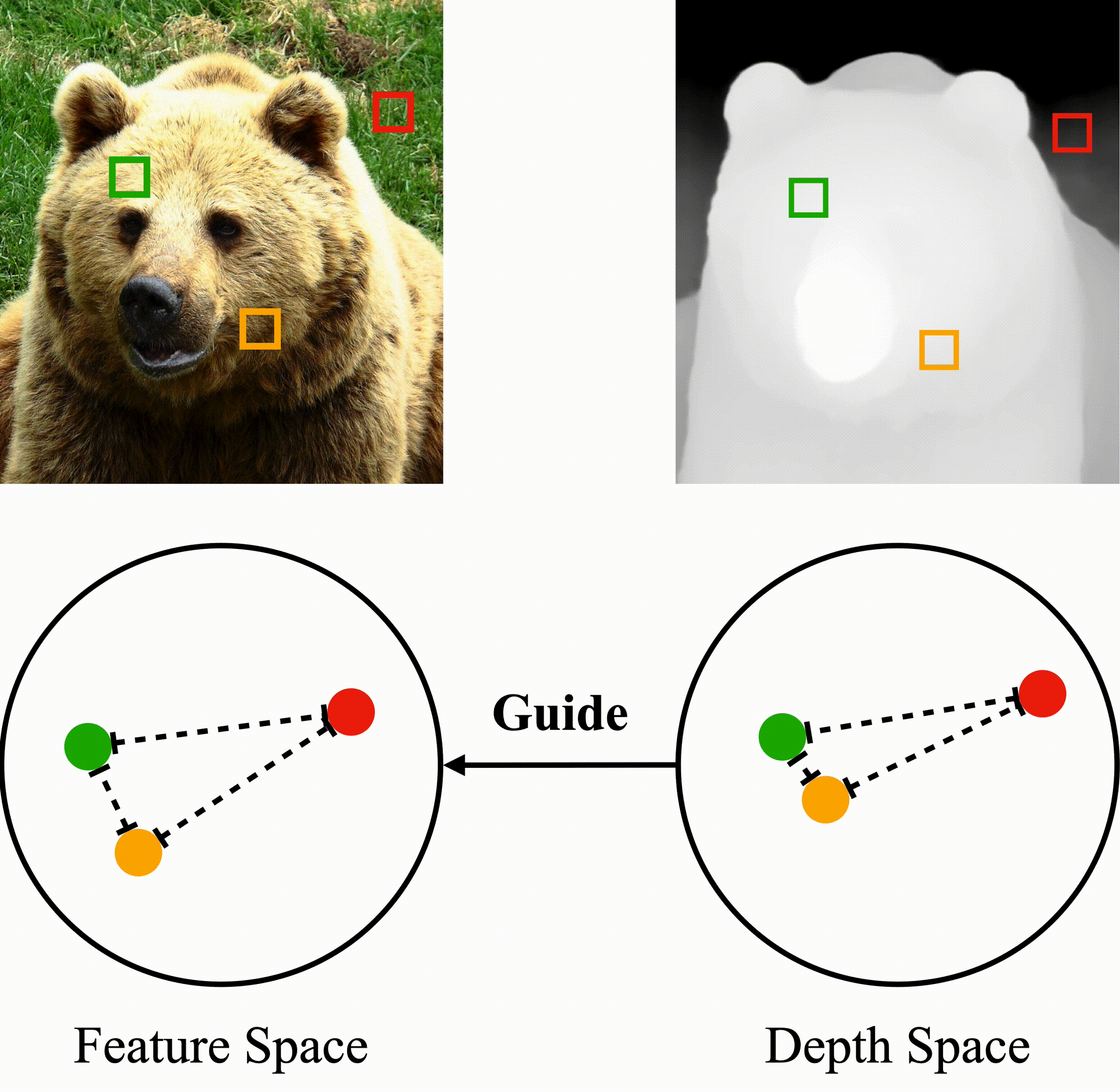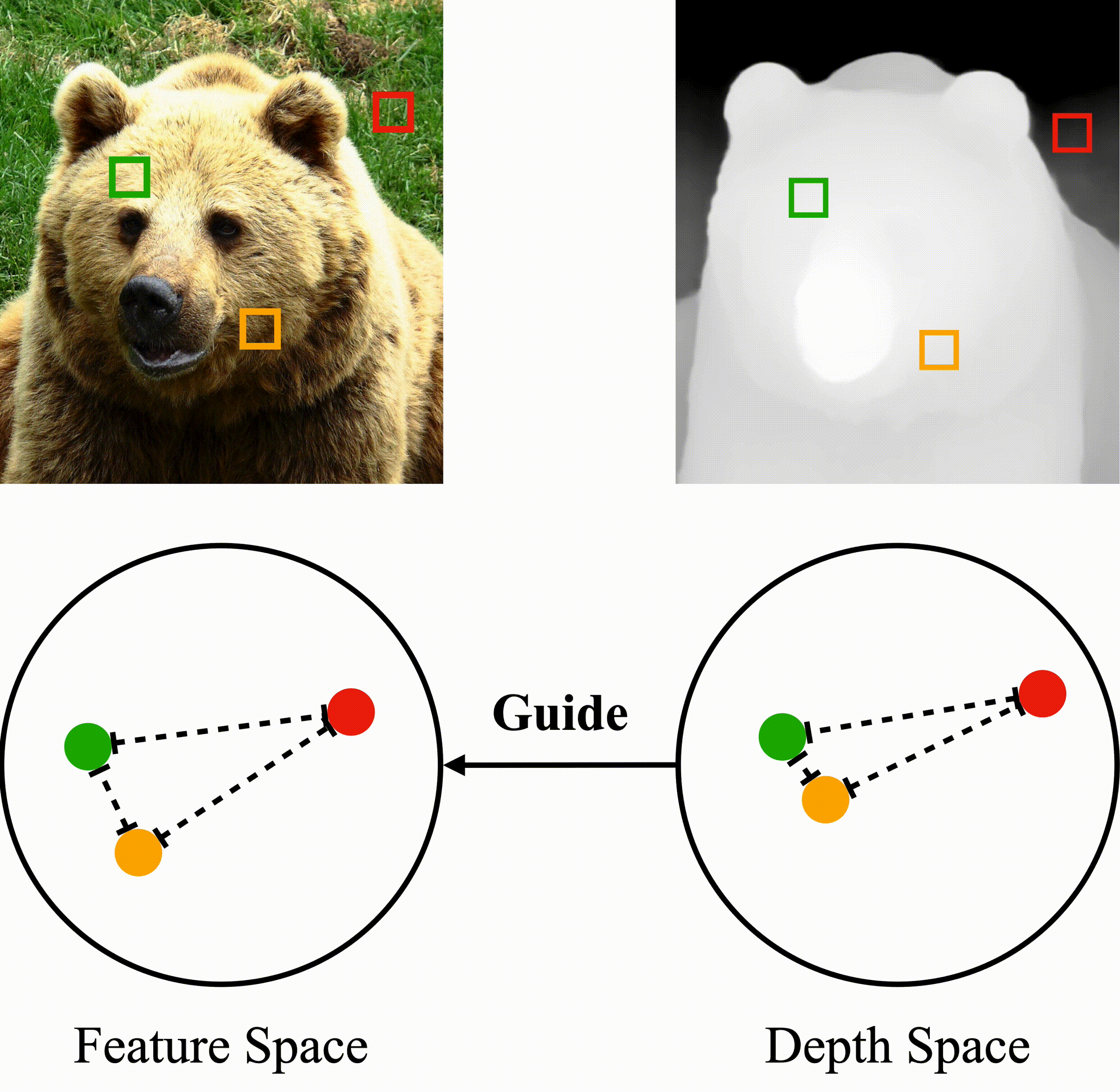
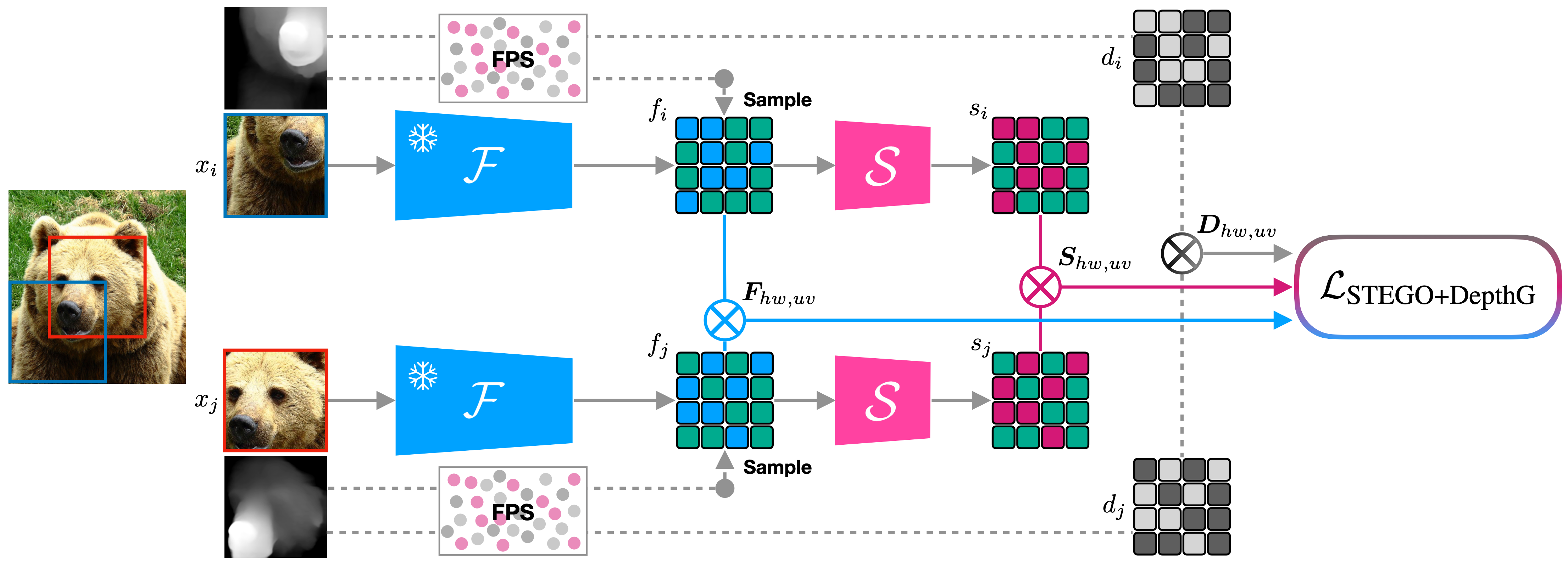
Farthest-Point Sampling
We observe that random sampling can miss entire structures like trees in the first top and the plane in the bottom row. In contrast, our method meaningfully samples the depth space and selects locations across the different structures and at depth edges.