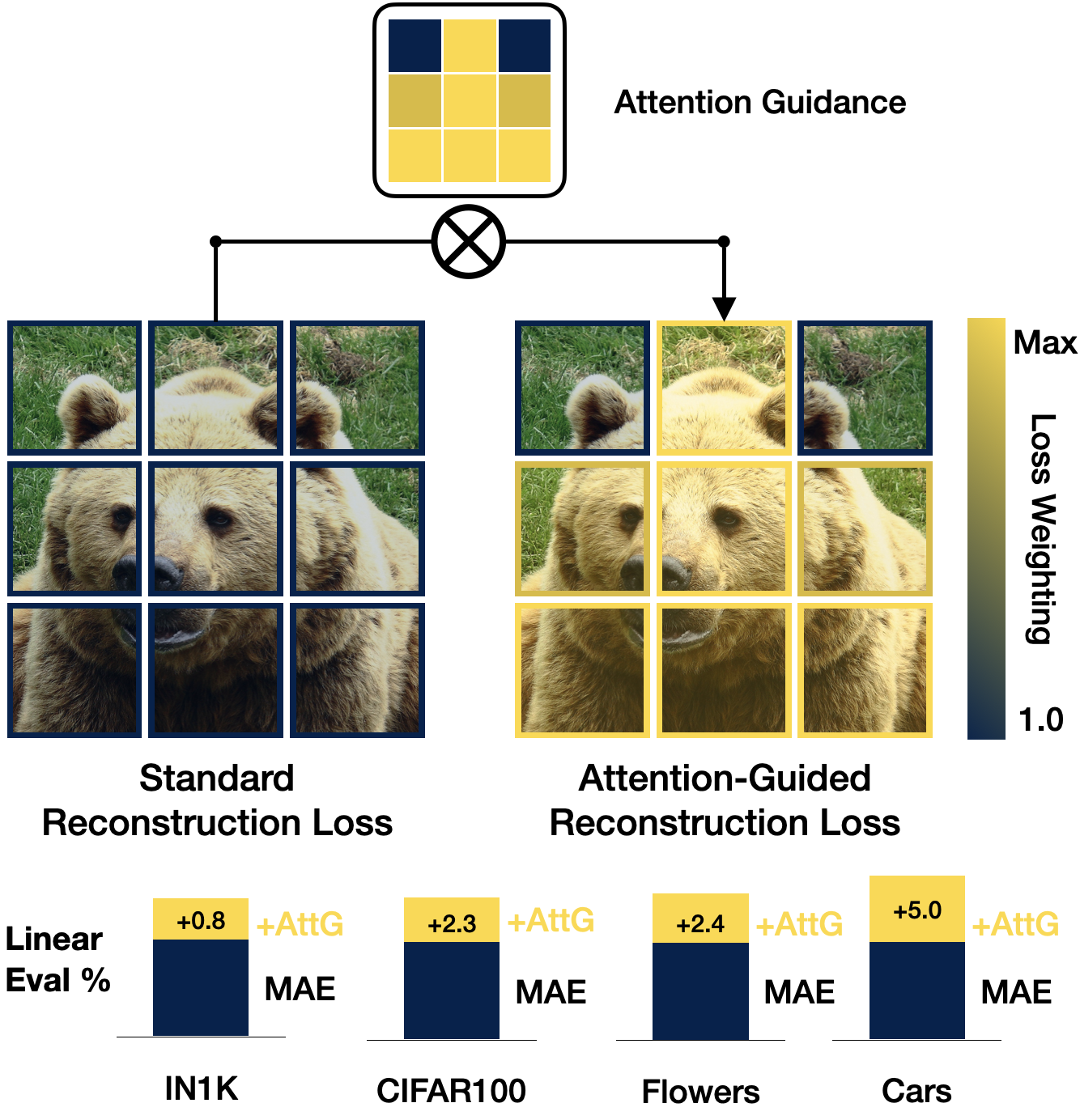
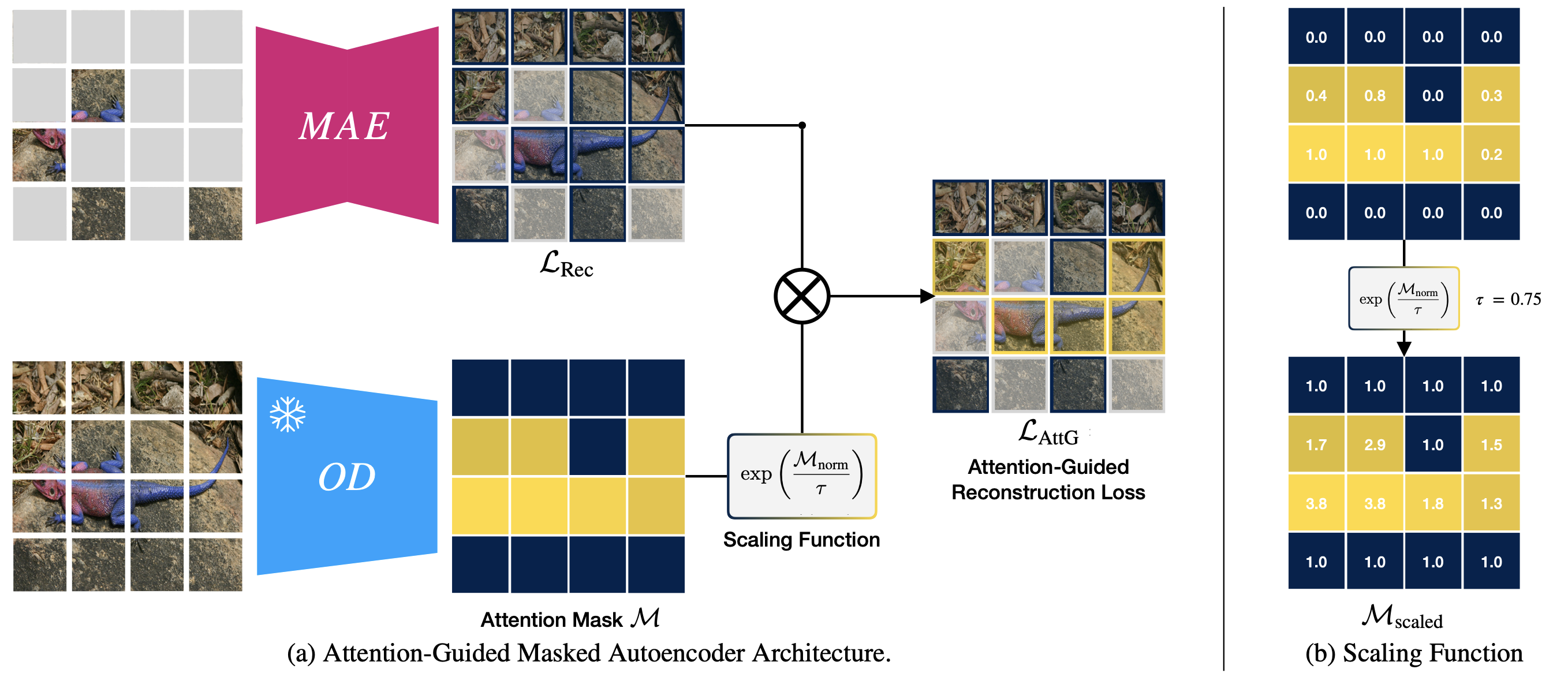
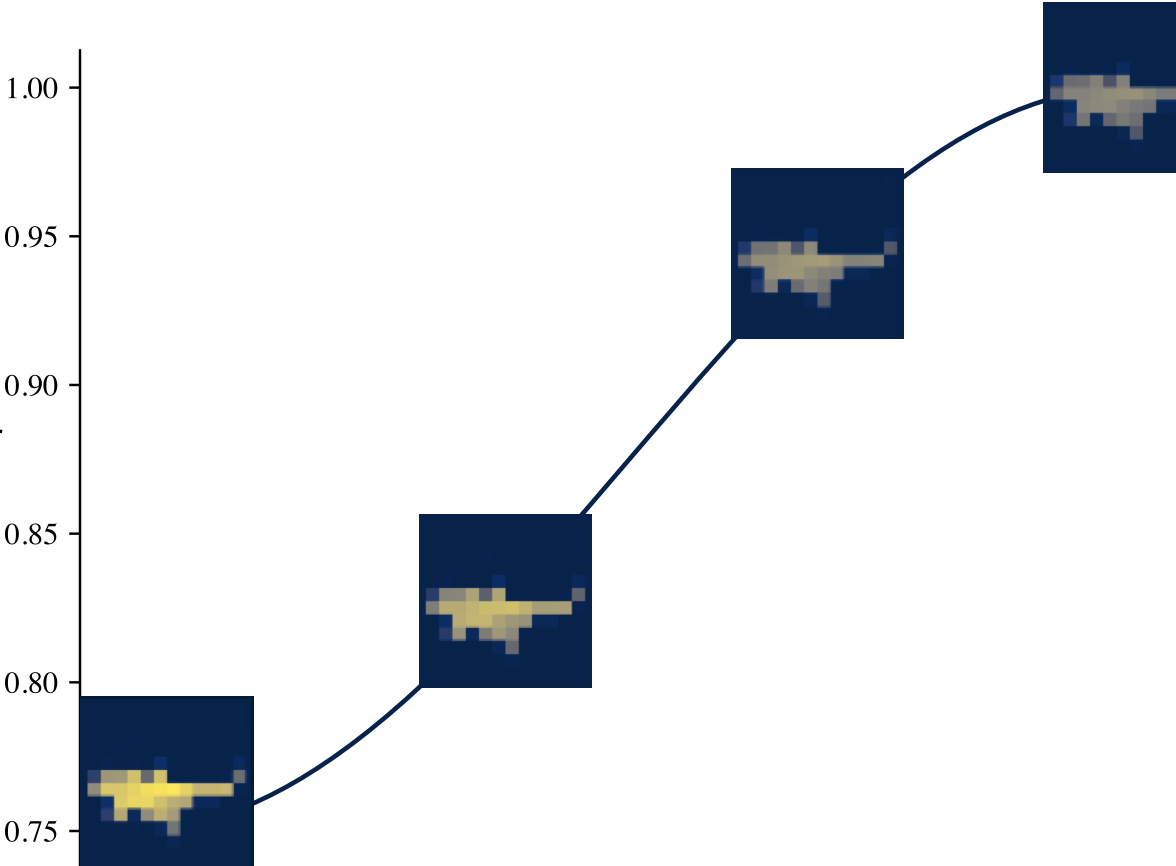
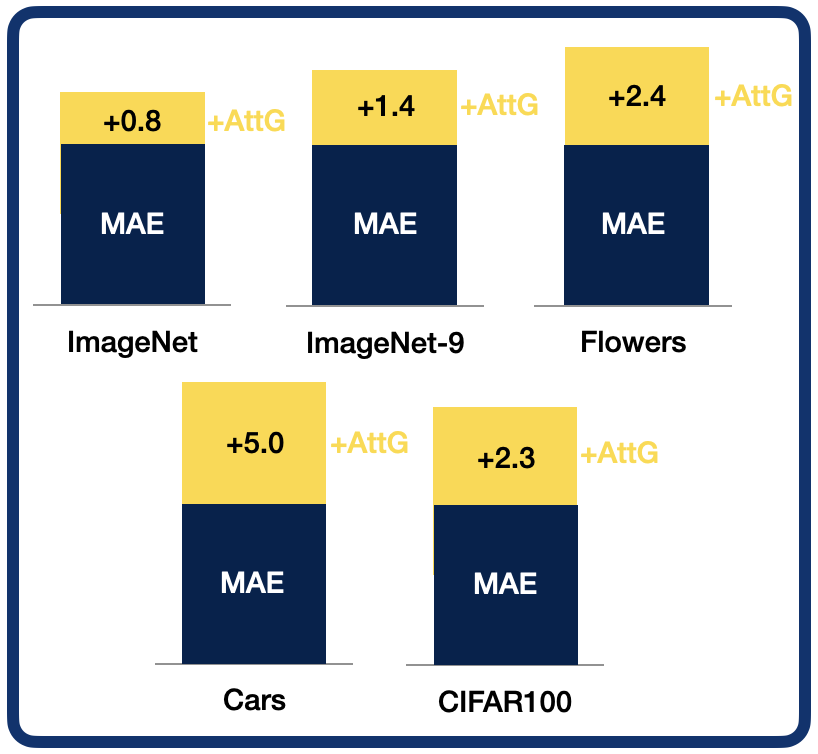
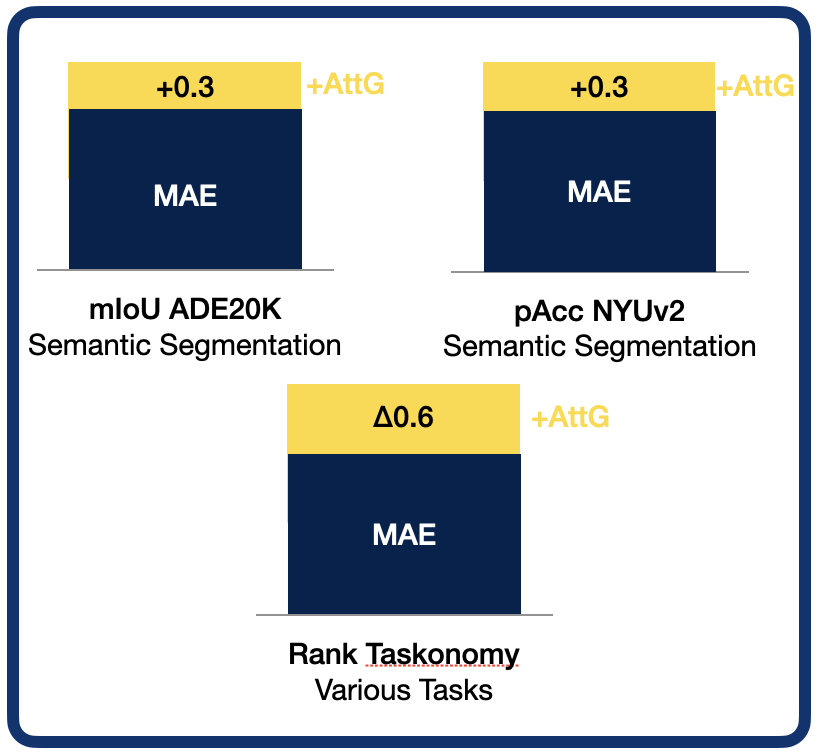
Following the standard Masked Autoencoder protocol, we first mask 75% of the image patches and pass it through the encoder-decoder architecture to reconstruct the masked patches and calculate the reconstruction loss. As for the MAE, this is simply the MSE between the decoded and original pixel values. At the same time, we pass the full image through our unsupervised object discovery network, TokenCut, to obtain the raw attention mask. A scalar value between 0 and 1, the foreground score, is assigned to every patch. We then pass this attention mask through our scaling function, where its normalized, sharpened with a temperature parameter tau, and inserted into the exponential function. We will go into the initiation and effect behind this design choice later.Finally, we multiply the scaled attention mask with the reconstructed loss of the reconstructed patches, effectively performing a semantic reweighing of the loss. We find this enables the model to put increased emphasis on the foreground object.